import tensorflow as tf
from tensorflow import keras as ks
from tensorflow.keras.datasets import mnist, fashion_mnist
from sklearn.model_selection import train_test_split
import numpy as np
from matplotlib import pyplot as plt
!pip install visualkeras
import visualkeras
from PIL import ImageFont
Collecting visualkeras Downloading visualkeras-0.1.4-py3-none-any.whl.metadata (11 kB) Requirement already satisfied: pillow>=6.2.0 in /usr/local/lib/python3.11/dist-packages (from visualkeras) (11.1.0) Requirement already satisfied: numpy>=1.18.1 in /usr/local/lib/python3.11/dist-packages (from visualkeras) (1.26.4) Collecting aggdraw>=1.3.11 (from visualkeras) Downloading aggdraw-1.3.19-cp311-cp311-manylinux_2_17_x86_64.manylinux2014_x86_64.whl.metadata (655 bytes) Downloading visualkeras-0.1.4-py3-none-any.whl (17 kB) Downloading aggdraw-1.3.19-cp311-cp311-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (997 kB) ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 997.4/997.4 kB 11.7 MB/s eta 0:00:00 Installing collected packages: aggdraw, visualkeras Successfully installed aggdraw-1.3.19 visualkeras-0.1.4
Blind source separation¶
Notebook realized for deep learning's university course @unibo a.y 2024/2025 February session by Michele Dinelli 0001132338.
This project aims to separate an image, formed as the sum of two images, into its original components.
The two source images, img1 and img2, are drawn from different datasets: MNIST and Fashion-MNIST, respectively.
No preprocessing is allowed. The neural network receives the combined image (img1 + img2) as input and outputs the predicted components (hat_img1,hat_img2).
Performance is evaluated using the mean squared error (MSE) between the predicted and ground-truth images.
Both datasets (MNIST and Fashion-MNIST) are grayscale. For simplicity, all samples are padded to a (32,32) resolution.
Here we load the two datasets, mnist and fashion mnist (both in grayscale).
For simplicity, the samples are padded to dimension (32,32).
(mnist_x_train, mnist_y_train), (mnist_x_test, mnist_y_test) = mnist.load_data()
mnist_x_train = np.pad(mnist_x_train,((0,0),(2,2),(2,2)))/255.
mnist_x_test = np.pad(mnist_x_test,((0,0),(2,2),(2,2)))/255.
print(f"mnist x train: {np.shape(mnist_x_train)}")
(fashion_mnist_x_train, fashion_mnist_y_train), (fashion_mnist_x_test, fashion_mnist_y_test) = fashion_mnist.load_data()
fashion_mnist_x_train = np.pad(fashion_mnist_x_train,((0,0),(2,2),(2,2)))/255.
fashion_mnist_x_test = np.pad(fashion_mnist_x_test,((0,0),(2,2),(2,2)))/255.
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/mnist.npz 11490434/11490434 ━━━━━━━━━━━━━━━━━━━━ 0s 0us/step mnist x train: (60000, 32, 32) Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-labels-idx1-ubyte.gz 29515/29515 ━━━━━━━━━━━━━━━━━━━━ 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-images-idx3-ubyte.gz 26421880/26421880 ━━━━━━━━━━━━━━━━━━━━ 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-labels-idx1-ubyte.gz 5148/5148 ━━━━━━━━━━━━━━━━━━━━ 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-images-idx3-ubyte.gz 4422102/4422102 ━━━━━━━━━━━━━━━━━━━━ 0s 0us/step
Here is a simple datagenerator.
def datagenerator(x1,x2,batchsize):
n1 = x1.shape[0]
n2 = x2.shape[0]
while True:
num1 = np.random.randint(0, n1, batchsize)
num2 = np.random.randint(0, n2, batchsize)
x_data = (x1[num1] + x2[num2]) / 2.0
y_data = (x1[num1], x2[num2])
yield x_data, y_data
Let us define a generator with batchsize=1 and let's test it.
onegen = datagenerator(mnist_x_test,fashion_mnist_x_test,1)
Let us look at some input-output pairs
def show_images(x,y1,y2):
fig, ax = plt.subplots(1,3,figsize=(12,4))
ax[0].imshow(x,cmap='gray')
ax[0].title.set_text('Input')
ax[0].axis('off')
ax[1].imshow(y1,cmap='gray')
ax[1].title.set_text('mnist')
ax[1].axis('off')
ax[2].imshow(y2,cmap='gray')
ax[2].title.set_text('fashion_mnist')
ax[2].axis('off')
plt.show()
x, (y1, y2) = next(onegen)
show_images(x[0], y1[0], y2[0])

Problem analysis¶
After some research, Blind Source Separation (BSS) appears to be a common problem for audio signal processing [1]. Audio separation technique has found its place in numerous practical applications and of course also in BSS image separation [1] [2] [3].
While looking for a suitable model architecture for the provided task I read about U-Net [4] architecture and how it was adapted to audio source separation tasks [5]. U-Net was originally proposed, as we saw, for Biomedical Image Segmentation but gained popularity for its incredible performances in image generation as it was also used as backbone for Stable Diffusion models [9].
U-Net consists of a encoder followed by a decoder connected by connection paths and a bottleneck. The encoder is responsible of exctracting features from the input image while the decoder is responsible of upsampling intermediate features and producing the final output. Encoder and decoder are symmetrical and connected, recalling the U shape, hence the name U-Net.
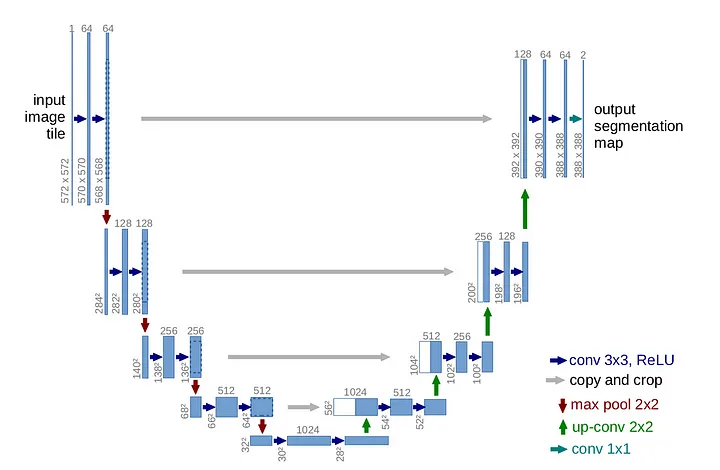{kind=link}
How U-Net works¶
Features are passed through the encoder which consists of repeated convolutional layers and max pooling layers to extract intermediate features. The extracted features are then upsampled by the corresponding decoder. Saved copies of the corresponding encoder's features are concatendated onto the decoder features using skip connections. In order to train the network, once the final layer produces the output, it is required to calculate the loss with respect of a ground truth image and then backpropagate the gradients through the network to improve predictions [4]). In this BSS problem context the ground truth images are 32x32 mixed images from MNIST and Fashion-MNIST.
- The Encoder: series of 3x3 convolutional layers at each of the stages. At the end of each stage ReLu activation function is applied to each feature. Between the stages a 2x2 max pooling opearation is applied to down-sample the features (the equivalent of picking the largest value in a non-overlapping window rolled across the image). This reduces the spatial dimensions of the features in fact channels are doubled after each max pooling operation.
- Decoder: series of 3x3 convolutional layers at each of the stages again followed by the ReLu activation function. After each stage Decoder upsamples the current set of features applying a 2x2 convolutional layer and halves the number of channels.
- Connecting paths (skip connections): they connect simmetrical parts of Encoder/Decoder and concatenate features from the Encoder on the opposing stage in the Decoder. This means subsequent convolutional layers can operate on both Encoder/Decoder features. Encoder's features should contain spatial information while Decoder's features should contain more semantic information. Comining information is key.
- Bottleneck: where the Encoder switches to Decoder. Features comming from the Encoder are down-sampled with 2x2 max pooling then again 3x3 convolutional layers + ReLu are applied, finally upsamled again.
Model proposed¶
The model proposed is a Convolutional Neural Network (CNN) that is inspired by U-Net architecture with some tweaks for the BSS problem. The model consists of 3 encoder/decoder blocks with 3 convolution layers for each block and skip connections between symmetrical encoder/decoder stages. I decided to keep it simple since the images are grayscale 32x32 and I wanted to test more configurations without commiting to a deeper network with tons of parameters which results in slower training (also considering that I am limited by the free-tier GPU usage on Google Colab and the runtime may die at anytime). I slightly modified model's output with respect of the original U-Net model because the problem stated that the model must return two predictions. I added two final convolution layers and then finally return two outputs: the two source images from MNIST and MNIST-Fashion.
On the number of filters¶
It's not always the higher the better of course [8]. There are no rules on how to decide number of filters but the original U-Net double them after each encoder stage so I just had to choose the starting number because I used the same approach.
On the final layer activation function¶
I tried to toogle the final layer activation function between ReLU and sigmoid and results were basically the same but ReLU was slightly better. I decided to keep it since outputs should be in a range that preserves fine details without forcing values into [0,1].
On activation functions¶
I also came across Leaky ReLU activation function and I considered to use it through the layers since some neurons may always output 0 permanently (dying ReLU [6] problem), if weights are updated poorly. Leaky ReLU prevents this by keeping a small negative slope but since the model isn't very deep I didn't pursued the idea. Allowing small negative values, may preserve too much noise rather than focusing on meaningful features.
On the dropout¶
Dropout is a regularization technique to prevent overfitting. It (pseudo)randomly disables a fraction of neurons during training so the network is forced to learn more robust features instead of relying on specific neurons. It can prevent overfitting and it is like training smaller networks and then averaging them. Of course there is some overhead introduced and slower convergence since not all the neurons are active. I thought about introducing dropout considering that I also had to make these adjustments: increase the network size and increase learning rate. Increasing the learning rate and ,maybe even adding momentum may result in large weight values so it should also a valid choice adding max-norm regularization [7]. I finally opted to avoid dropout.
On the batch normalization¶
During training of a neural network, the distribution of the input values of each layer is affected by all layers that come before it. This variability reduces training speed (lower learning rates). Batch normalization was created to resolve this variability and speed up learning [7]. The way batch normalization operates, by adjusting the value of the units for each batch, and the fact that batches are created randomly during training, results in more noise during the training process. The noise acts as a regularizer. This regularization effect is similar to the one introduced by dropout. As a result, dropout can be removed completely from the network or should have its rate reduced significantly if used in conjunction with batch normalization. I chose to add batch normalization since it was proven to be effective in CNN training stabilization carrying the best result in similar tasks [7]).
References¶
- Blind source separation: A review and analysis
- Blind Separation Of Reflections Using The Image Mixtures Ratio
- Efficient Separation of Convolutive Image Mixtures
- U-Net: Convolutional Networks for Biomedical Image Segmentation
- Blind source separation based on improved Wave-U-Net network
- Dying ReLU and Initialization: Theory and Numerical Examples
- Dropout vs. batch normalization: an empirical study of their impact to deep learning
- The Impact of Filter Size and Number of Filters on Classification Accuracy in CNN
- FreeU: Free Lunch in Diffusion U-Net
def encoder_block(inputs, layer_idx, total_blocks, num_channels, conv_layers_per_block, skip_connections):
x = inputs
for _ in range(conv_layers_per_block):
x = ks.layers.Conv2D(num_channels, kernel_size=3, padding='same')(x)
x = ks.layers.BatchNormalization()(x)
x = ks.layers.ReLU()(x)
if layer_idx < total_blocks - 1:
skip_connections.append(x) # Store the features for skip connections
x = ks.layers.MaxPooling2D(pool_size=(2, 2), padding='same')(x)
num_channels *= 2 # Double channels
return x, num_channels
def decoder_block(inputs, layer_idx, total_blocks, num_channels, conv_layers_per_block, skip_connections):
num_channels //= 2 # Halves channels
h = ks.layers.Conv2DTranspose(num_channels, 3, strides=2, padding='same')(inputs)
skip_features = skip_connections.pop(-1)
x = ks.layers.Concatenate()([h, skip_features])
for _ in range(conv_layers_per_block):
x = ks.layers.Conv2D(num_channels, kernel_size=3, padding='same')(x)
x = ks.layers.BatchNormalization()(x)
x = ks.layers.ReLU()(x)
return x, num_channels
def build_model(input_shape, initial_channels=32, num_blocks=4, conv_layers_per_block=2):
inputs = ks.layers.Input(shape=input_shape)
skip_connections = []
x = inputs
num_channels = initial_channels
for block_idx in range(num_blocks):
x, num_channels = encoder_block(x, block_idx, num_blocks, num_channels, conv_layers_per_block, skip_connections)
for block_idx in range(num_blocks - 1):
x, num_channels = decoder_block(x, block_idx, num_blocks, num_channels, conv_layers_per_block, skip_connections)
output_mnist = ks.layers.Conv2D(1, kernel_size=1, activation='relu', name='mnist_out')(x)
output_fashion_mnist = ks.layers.Conv2D(1, kernel_size=1, activation='relu', name='fashion_mnist_out')(x)
return ks.models.Model(inputs, [output_mnist, output_fashion_mnist])
model = build_model(input_shape=(32, 32, 1), initial_channels=64, num_blocks=3, conv_layers_per_block=3)
model.summary()
Model: "functional"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━┓ ┃ Layer (type) ┃ Output Shape ┃ Param # ┃ Connected to ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━┩ │ input_layer (InputLayer) │ (None, 32, 32, 1) │ 0 │ - │ ├───────────────────────────┼────────────────────────┼────────────────┼────────────────────────┤ │ conv2d (Conv2D) │ (None, 32, 32, 64) │ 640 │ input_layer[0][0] │ ├───────────────────────────┼────────────────────────┼────────────────┼────────────────────────┤ │ batch_normalization │ (None, 32, 32, 64) │ 256 │ conv2d[0][0] │ │ (BatchNormalization) │ │ │ │ ├───────────────────────────┼────────────────────────┼────────────────┼────────────────────────┤ │ re_lu (ReLU) │ (None, 32, 32, 64) │ 0 │ batch_normalization[0… │ ├───────────────────────────┼────────────────────────┼────────────────┼────────────────────────┤ │ conv2d_1 (Conv2D) │ (None, 32, 32, 64) │ 36,928 │ re_lu[0][0] │ ├───────────────────────────┼────────────────────────┼────────────────┼────────────────────────┤ │ batch_normalization_1 │ (None, 32, 32, 64) │ 256 │ conv2d_1[0][0] │ │ (BatchNormalization) │ │ │ │ ├───────────────────────────┼────────────────────────┼────────────────┼────────────────────────┤ │ re_lu_1 (ReLU) │ (None, 32, 32, 64) │ 0 │ batch_normalization_1… │ ├───────────────────────────┼────────────────────────┼────────────────┼────────────────────────┤ │ conv2d_2 (Conv2D) │ (None, 32, 32, 64) │ 36,928 │ re_lu_1[0][0] │ ├───────────────────────────┼────────────────────────┼────────────────┼────────────────────────┤ │ batch_normalization_2 │ (None, 32, 32, 64) │ 256 │ conv2d_2[0][0] │ │ (BatchNormalization) │ │ │ │ ├───────────────────────────┼────────────────────────┼────────────────┼────────────────────────┤ │ re_lu_2 (ReLU) │ (None, 32, 32, 64) │ 0 │ batch_normalization_2… │ ├───────────────────────────┼────────────────────────┼────────────────┼────────────────────────┤ │ max_pooling2d │ (None, 16, 16, 64) │ 0 │ re_lu_2[0][0] │ │ (MaxPooling2D) │ │ │ │ ├───────────────────────────┼────────────────────────┼────────────────┼────────────────────────┤ │ conv2d_3 (Conv2D) │ (None, 16, 16, 128) │ 73,856 │ max_pooling2d[0][0] │ ├───────────────────────────┼────────────────────────┼────────────────┼────────────────────────┤ │ batch_normalization_3 │ (None, 16, 16, 128) │ 512 │ conv2d_3[0][0] │ │ (BatchNormalization) │ │ │ │ ├───────────────────────────┼────────────────────────┼────────────────┼────────────────────────┤ │ re_lu_3 (ReLU) │ (None, 16, 16, 128) │ 0 │ batch_normalization_3… │ ├───────────────────────────┼────────────────────────┼────────────────┼────────────────────────┤ │ conv2d_4 (Conv2D) │ (None, 16, 16, 128) │ 147,584 │ re_lu_3[0][0] │ ├───────────────────────────┼────────────────────────┼────────────────┼────────────────────────┤ │ batch_normalization_4 │ (None, 16, 16, 128) │ 512 │ conv2d_4[0][0] │ │ (BatchNormalization) │ │ │ │ ├───────────────────────────┼────────────────────────┼────────────────┼────────────────────────┤ │ re_lu_4 (ReLU) │ (None, 16, 16, 128) │ 0 │ batch_normalization_4… │ ├───────────────────────────┼────────────────────────┼────────────────┼────────────────────────┤ │ conv2d_5 (Conv2D) │ (None, 16, 16, 128) │ 147,584 │ re_lu_4[0][0] │ ├───────────────────────────┼────────────────────────┼────────────────┼────────────────────────┤ │ batch_normalization_5 │ (None, 16, 16, 128) │ 512 │ conv2d_5[0][0] │ │ (BatchNormalization) │ │ │ │ ├───────────────────────────┼────────────────────────┼────────────────┼────────────────────────┤ │ re_lu_5 (ReLU) │ (None, 16, 16, 128) │ 0 │ batch_normalization_5… │ ├───────────────────────────┼────────────────────────┼────────────────┼────────────────────────┤ │ max_pooling2d_1 │ (None, 8, 8, 128) │ 0 │ re_lu_5[0][0] │ │ (MaxPooling2D) │ │ │ │ ├───────────────────────────┼────────────────────────┼────────────────┼────────────────────────┤ │ conv2d_6 (Conv2D) │ (None, 8, 8, 256) │ 295,168 │ max_pooling2d_1[0][0] │ ├───────────────────────────┼────────────────────────┼────────────────┼────────────────────────┤ │ batch_normalization_6 │ (None, 8, 8, 256) │ 1,024 │ conv2d_6[0][0] │ │ (BatchNormalization) │ │ │ │ ├───────────────────────────┼────────────────────────┼────────────────┼────────────────────────┤ │ re_lu_6 (ReLU) │ (None, 8, 8, 256) │ 0 │ batch_normalization_6… │ ├───────────────────────────┼────────────────────────┼────────────────┼────────────────────────┤ │ conv2d_7 (Conv2D) │ (None, 8, 8, 256) │ 590,080 │ re_lu_6[0][0] │ ├───────────────────────────┼────────────────────────┼────────────────┼────────────────────────┤ │ batch_normalization_7 │ (None, 8, 8, 256) │ 1,024 │ conv2d_7[0][0] │ │ (BatchNormalization) │ │ │ │ ├───────────────────────────┼────────────────────────┼────────────────┼────────────────────────┤ │ re_lu_7 (ReLU) │ (None, 8, 8, 256) │ 0 │ batch_normalization_7… │ ├───────────────────────────┼────────────────────────┼────────────────┼────────────────────────┤ │ conv2d_8 (Conv2D) │ (None, 8, 8, 256) │ 590,080 │ re_lu_7[0][0] │ ├───────────────────────────┼────────────────────────┼────────────────┼────────────────────────┤ │ batch_normalization_8 │ (None, 8, 8, 256) │ 1,024 │ conv2d_8[0][0] │ │ (BatchNormalization) │ │ │ │ ├───────────────────────────┼────────────────────────┼────────────────┼────────────────────────┤ │ re_lu_8 (ReLU) │ (None, 8, 8, 256) │ 0 │ batch_normalization_8… │ ├───────────────────────────┼────────────────────────┼────────────────┼────────────────────────┤ │ conv2d_transpose │ (None, 16, 16, 128) │ 295,040 │ re_lu_8[0][0] │ │ (Conv2DTranspose) │ │ │ │ ├───────────────────────────┼────────────────────────┼────────────────┼────────────────────────┤ │ concatenate (Concatenate) │ (None, 16, 16, 256) │ 0 │ conv2d_transpose[0][0… │ │ │ │ │ re_lu_5[0][0] │ ├───────────────────────────┼────────────────────────┼────────────────┼────────────────────────┤ │ conv2d_9 (Conv2D) │ (None, 16, 16, 128) │ 295,040 │ concatenate[0][0] │ ├───────────────────────────┼────────────────────────┼────────────────┼────────────────────────┤ │ batch_normalization_9 │ (None, 16, 16, 128) │ 512 │ conv2d_9[0][0] │ │ (BatchNormalization) │ │ │ │ ├───────────────────────────┼────────────────────────┼────────────────┼────────────────────────┤ │ re_lu_9 (ReLU) │ (None, 16, 16, 128) │ 0 │ batch_normalization_9… │ ├───────────────────────────┼────────────────────────┼────────────────┼────────────────────────┤ │ conv2d_10 (Conv2D) │ (None, 16, 16, 128) │ 147,584 │ re_lu_9[0][0] │ ├───────────────────────────┼────────────────────────┼────────────────┼────────────────────────┤ │ batch_normalization_10 │ (None, 16, 16, 128) │ 512 │ conv2d_10[0][0] │ │ (BatchNormalization) │ │ │ │ ├───────────────────────────┼────────────────────────┼────────────────┼────────────────────────┤ │ re_lu_10 (ReLU) │ (None, 16, 16, 128) │ 0 │ batch_normalization_1… │ ├───────────────────────────┼────────────────────────┼────────────────┼────────────────────────┤ │ conv2d_11 (Conv2D) │ (None, 16, 16, 128) │ 147,584 │ re_lu_10[0][0] │ ├───────────────────────────┼────────────────────────┼────────────────┼────────────────────────┤ │ batch_normalization_11 │ (None, 16, 16, 128) │ 512 │ conv2d_11[0][0] │ │ (BatchNormalization) │ │ │ │ ├───────────────────────────┼────────────────────────┼────────────────┼────────────────────────┤ │ re_lu_11 (ReLU) │ (None, 16, 16, 128) │ 0 │ batch_normalization_1… │ ├───────────────────────────┼────────────────────────┼────────────────┼────────────────────────┤ │ conv2d_transpose_1 │ (None, 32, 32, 64) │ 73,792 │ re_lu_11[0][0] │ │ (Conv2DTranspose) │ │ │ │ ├───────────────────────────┼────────────────────────┼────────────────┼────────────────────────┤ │ concatenate_1 │ (None, 32, 32, 128) │ 0 │ conv2d_transpose_1[0]… │ │ (Concatenate) │ │ │ re_lu_2[0][0] │ ├───────────────────────────┼────────────────────────┼────────────────┼────────────────────────┤ │ conv2d_12 (Conv2D) │ (None, 32, 32, 64) │ 73,792 │ concatenate_1[0][0] │ ├───────────────────────────┼────────────────────────┼────────────────┼────────────────────────┤ │ batch_normalization_12 │ (None, 32, 32, 64) │ 256 │ conv2d_12[0][0] │ │ (BatchNormalization) │ │ │ │ ├───────────────────────────┼────────────────────────┼────────────────┼────────────────────────┤ │ re_lu_12 (ReLU) │ (None, 32, 32, 64) │ 0 │ batch_normalization_1… │ ├───────────────────────────┼────────────────────────┼────────────────┼────────────────────────┤ │ conv2d_13 (Conv2D) │ (None, 32, 32, 64) │ 36,928 │ re_lu_12[0][0] │ ├───────────────────────────┼────────────────────────┼────────────────┼────────────────────────┤ │ batch_normalization_13 │ (None, 32, 32, 64) │ 256 │ conv2d_13[0][0] │ │ (BatchNormalization) │ │ │ │ ├───────────────────────────┼────────────────────────┼────────────────┼────────────────────────┤ │ re_lu_13 (ReLU) │ (None, 32, 32, 64) │ 0 │ batch_normalization_1… │ ├───────────────────────────┼────────────────────────┼────────────────┼────────────────────────┤ │ conv2d_14 (Conv2D) │ (None, 32, 32, 64) │ 36,928 │ re_lu_13[0][0] │ ├───────────────────────────┼────────────────────────┼────────────────┼────────────────────────┤ │ batch_normalization_14 │ (None, 32, 32, 64) │ 256 │ conv2d_14[0][0] │ │ (BatchNormalization) │ │ │ │ ├───────────────────────────┼────────────────────────┼────────────────┼────────────────────────┤ │ re_lu_14 (ReLU) │ (None, 32, 32, 64) │ 0 │ batch_normalization_1… │ ├───────────────────────────┼────────────────────────┼────────────────┼────────────────────────┤ │ mnist_out (Conv2D) │ (None, 32, 32, 1) │ 65 │ re_lu_14[0][0] │ ├───────────────────────────┼────────────────────────┼────────────────┼────────────────────────┤ │ fashion_mnist_out │ (None, 32, 32, 1) │ 65 │ re_lu_14[0][0] │ │ (Conv2D) │ │ │ │ └───────────────────────────┴────────────────────────┴────────────────┴────────────────────────┘
Total params: 3,033,346 (11.57 MB)
Trainable params: 3,029,506 (11.56 MB)
Non-trainable params: 3,840 (15.00 KB)
font = ImageFont.load_default(size=22)
visualkeras.layered_view(model, legend=True, font=font, show_dimension=True, scale_xy=12, spacing=25, padding=50)

Training¶
The model has been trained multiple times with hyperparameter tuning between each round of training. The notebook will report only the last training round. Some training data are sacrificed for validation purposes.
I chose Adam as optimizer which is pretty standard and 32 as batch size. The number of steps per epoch is a function of the number of training samples and the batch size. I tried also adding a constant factor to increase the number of steps per epoch but the default configuration (train_samples // batch_size) appears to behave well. I decided to train the model for 150 epochs which probably can be a little too much so I added a callback for early stopping with patience = 10. I also added a model checkpoint callback to store what are considered the best weights. Finally I added a callback to reduce learning rate on plateau with patience = 8 and min_lr = 1e-5 while the initial learning rate is set to 1e-3. I did not specify how to weight each individual output so the shared loss function will be handled by Keras, the default behaviour is computing the loss as the sum of the losses. I considered that the default behaviour i.e. summing losses keeps the absolute magnitude of losses but if one has a much larger loss, it can dominate training. Losses seem to float in the same ranges so I decided to leave it as default.
mnist_train, mnist_val = train_test_split(mnist_x_train, test_size=0.1)
fashion_mnist_train, fashion_mnist_val = train_test_split(fashion_mnist_x_train, test_size=0.1)
train_samples = mnist_train.shape[0]
val_samples = mnist_val.shape[0]
print(f'MNIST\nTrain set: {mnist_train.shape}\nValidation set: {mnist_val.shape}\n')
print(f'Fashion MNIST\nTrain set: {fashion_mnist_train.shape}\nValidation set: {fashion_mnist_val.shape}')
MNIST Train set: (54000, 32, 32) Validation set: (6000, 32, 32) Fashion MNIST Train set: (54000, 32, 32) Validation set: (6000, 32, 32)
batch_size = 32
learning_rate = 1e-3
epochs = 150
steps_per_epoch = train_samples // batch_size
validation_steps = val_samples // batch_size
train_generator = datagenerator(mnist_train, fashion_mnist_train, batch_size)
val_generator = datagenerator(mnist_val, fashion_mnist_val, batch_size)
callbacks = [
ks.callbacks.ReduceLROnPlateau(monitor='val_loss', factor=0.3, patience=8, min_lr=1e-5, mode='min', verbose=1),
ks.callbacks.ModelCheckpoint(filepath="best.weights.h5", save_weights_only=True, monitor='val_loss', mode='min', save_best_only=True, verbose=1),
ks.callbacks.EarlyStopping(monitor='val_loss', patience=10, restore_best_weights=True, verbose=1)
]
optimizer = ks.optimizers.Adam(learning_rate=learning_rate)
model.compile(optimizer=optimizer, loss='mse', metrics=['mse', 'mse'])
history = model.fit(
train_generator,
steps_per_epoch=steps_per_epoch,
validation_data=val_generator,
validation_steps=validation_steps,
epochs=epochs,
callbacks=callbacks
)
Epoch 1/150 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 0s 32ms/step - fashion_mnist_out_loss: 0.0178 - fashion_mnist_out_mse: 0.0178 - loss: 0.0263 - mnist_out_loss: 0.0085 - mnist_out_mse: 0.0085 Epoch 1: val_loss improved from inf to 0.00454, saving model to best.weights.h5 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 79s 34ms/step - fashion_mnist_out_loss: 0.0178 - fashion_mnist_out_mse: 0.0178 - loss: 0.0263 - mnist_out_loss: 0.0085 - mnist_out_mse: 0.0085 - val_fashion_mnist_out_loss: 0.0027 - val_fashion_mnist_out_mse: 0.0027 - val_loss: 0.0045 - val_mnist_out_loss: 0.0019 - val_mnist_out_mse: 0.0019 - learning_rate: 0.0010 Epoch 2/150 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 0s 33ms/step - fashion_mnist_out_loss: 0.0022 - fashion_mnist_out_mse: 0.0022 - loss: 0.0039 - mnist_out_loss: 0.0016 - mnist_out_mse: 0.0016 Epoch 2: val_loss improved from 0.00454 to 0.00377, saving model to best.weights.h5 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 59s 35ms/step - fashion_mnist_out_loss: 0.0022 - fashion_mnist_out_mse: 0.0022 - loss: 0.0039 - mnist_out_loss: 0.0016 - mnist_out_mse: 0.0016 - val_fashion_mnist_out_loss: 0.0022 - val_fashion_mnist_out_mse: 0.0022 - val_loss: 0.0038 - val_mnist_out_loss: 0.0016 - val_mnist_out_mse: 0.0016 - learning_rate: 0.0010 Epoch 3/150 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 0s 33ms/step - fashion_mnist_out_loss: 0.0017 - fashion_mnist_out_mse: 0.0017 - loss: 0.0031 - mnist_out_loss: 0.0013 - mnist_out_mse: 0.0013 Epoch 3: val_loss improved from 0.00377 to 0.00237, saving model to best.weights.h5 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 82s 49ms/step - fashion_mnist_out_loss: 0.0017 - fashion_mnist_out_mse: 0.0017 - loss: 0.0031 - mnist_out_loss: 0.0013 - mnist_out_mse: 0.0013 - val_fashion_mnist_out_loss: 0.0013 - val_fashion_mnist_out_mse: 0.0013 - val_loss: 0.0024 - val_mnist_out_loss: 0.0011 - val_mnist_out_mse: 0.0011 - learning_rate: 0.0010 Epoch 4/150 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 0s 33ms/step - fashion_mnist_out_loss: 0.0015 - fashion_mnist_out_mse: 0.0015 - loss: 0.0026 - mnist_out_loss: 0.0011 - mnist_out_mse: 0.0011 Epoch 4: val_loss did not improve from 0.00237 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 58s 34ms/step - fashion_mnist_out_loss: 0.0015 - fashion_mnist_out_mse: 0.0015 - loss: 0.0026 - mnist_out_loss: 0.0011 - mnist_out_mse: 0.0011 - val_fashion_mnist_out_loss: 0.0014 - val_fashion_mnist_out_mse: 0.0014 - val_loss: 0.0027 - val_mnist_out_loss: 0.0013 - val_mnist_out_mse: 0.0013 - learning_rate: 0.0010 Epoch 5/150 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 0s 33ms/step - fashion_mnist_out_loss: 0.0013 - fashion_mnist_out_mse: 0.0013 - loss: 0.0023 - mnist_out_loss: 0.0010 - mnist_out_mse: 0.0010 Epoch 5: val_loss improved from 0.00237 to 0.00187, saving model to best.weights.h5 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 82s 49ms/step - fashion_mnist_out_loss: 0.0013 - fashion_mnist_out_mse: 0.0013 - loss: 0.0023 - mnist_out_loss: 0.0010 - mnist_out_mse: 0.0010 - val_fashion_mnist_out_loss: 9.9864e-04 - val_fashion_mnist_out_mse: 9.9864e-04 - val_loss: 0.0019 - val_mnist_out_loss: 8.6828e-04 - val_mnist_out_mse: 8.6828e-04 - learning_rate: 0.0010 Epoch 6/150 1686/1687 ━━━━━━━━━━━━━━━━━━━━ 0s 34ms/step - fashion_mnist_out_loss: 0.0011 - fashion_mnist_out_mse: 0.0011 - loss: 0.0020 - mnist_out_loss: 9.0666e-04 - mnist_out_mse: 9.0666e-04 Epoch 6: val_loss improved from 0.00187 to 0.00165, saving model to best.weights.h5 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 82s 49ms/step - fashion_mnist_out_loss: 0.0011 - fashion_mnist_out_mse: 0.0011 - loss: 0.0020 - mnist_out_loss: 9.0665e-04 - mnist_out_mse: 9.0665e-04 - val_fashion_mnist_out_loss: 8.7319e-04 - val_fashion_mnist_out_mse: 8.7319e-04 - val_loss: 0.0017 - val_mnist_out_loss: 7.8012e-04 - val_mnist_out_mse: 7.8012e-04 - learning_rate: 0.0010 Epoch 7/150 1686/1687 ━━━━━━━━━━━━━━━━━━━━ 0s 33ms/step - fashion_mnist_out_loss: 0.0010 - fashion_mnist_out_mse: 0.0010 - loss: 0.0019 - mnist_out_loss: 8.2103e-04 - mnist_out_mse: 8.2103e-04 Epoch 7: val_loss did not improve from 0.00165 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 58s 34ms/step - fashion_mnist_out_loss: 0.0010 - fashion_mnist_out_mse: 0.0010 - loss: 0.0019 - mnist_out_loss: 8.2104e-04 - mnist_out_mse: 8.2104e-04 - val_fashion_mnist_out_loss: 9.0077e-04 - val_fashion_mnist_out_mse: 9.0077e-04 - val_loss: 0.0017 - val_mnist_out_loss: 7.9944e-04 - val_mnist_out_mse: 7.9944e-04 - learning_rate: 0.0010 Epoch 8/150 1686/1687 ━━━━━━━━━━━━━━━━━━━━ 0s 33ms/step - fashion_mnist_out_loss: 9.9041e-04 - fashion_mnist_out_mse: 9.9041e-04 - loss: 0.0018 - mnist_out_loss: 7.9840e-04 - mnist_out_mse: 7.9840e-04 Epoch 8: val_loss did not improve from 0.00165 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 82s 49ms/step - fashion_mnist_out_loss: 9.9039e-04 - fashion_mnist_out_mse: 9.9039e-04 - loss: 0.0018 - mnist_out_loss: 7.9839e-04 - mnist_out_mse: 7.9839e-04 - val_fashion_mnist_out_loss: 0.0013 - val_fashion_mnist_out_mse: 0.0013 - val_loss: 0.0021 - val_mnist_out_loss: 8.5928e-04 - val_mnist_out_mse: 8.5928e-04 - learning_rate: 0.0010 Epoch 9/150 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 0s 33ms/step - fashion_mnist_out_loss: 9.4093e-04 - fashion_mnist_out_mse: 9.4093e-04 - loss: 0.0017 - mnist_out_loss: 7.5233e-04 - mnist_out_mse: 7.5233e-04 Epoch 9: val_loss improved from 0.00165 to 0.00148, saving model to best.weights.h5 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 82s 49ms/step - fashion_mnist_out_loss: 9.4092e-04 - fashion_mnist_out_mse: 9.4092e-04 - loss: 0.0017 - mnist_out_loss: 7.5233e-04 - mnist_out_mse: 7.5233e-04 - val_fashion_mnist_out_loss: 8.0637e-04 - val_fashion_mnist_out_mse: 8.0637e-04 - val_loss: 0.0015 - val_mnist_out_loss: 6.7758e-04 - val_mnist_out_mse: 6.7758e-04 - learning_rate: 0.0010 Epoch 10/150 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 0s 33ms/step - fashion_mnist_out_loss: 8.5704e-04 - fashion_mnist_out_mse: 8.5704e-04 - loss: 0.0016 - mnist_out_loss: 6.9987e-04 - mnist_out_mse: 6.9987e-04 Epoch 10: val_loss improved from 0.00148 to 0.00138, saving model to best.weights.h5 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 82s 49ms/step - fashion_mnist_out_loss: 8.5704e-04 - fashion_mnist_out_mse: 8.5704e-04 - loss: 0.0016 - mnist_out_loss: 6.9987e-04 - mnist_out_mse: 6.9987e-04 - val_fashion_mnist_out_loss: 7.2217e-04 - val_fashion_mnist_out_mse: 7.2217e-04 - val_loss: 0.0014 - val_mnist_out_loss: 6.5346e-04 - val_mnist_out_mse: 6.5346e-04 - learning_rate: 0.0010 Epoch 11/150 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 0s 33ms/step - fashion_mnist_out_loss: 7.9070e-04 - fashion_mnist_out_mse: 7.9070e-04 - loss: 0.0014 - mnist_out_loss: 6.5405e-04 - mnist_out_mse: 6.5405e-04 Epoch 11: val_loss improved from 0.00138 to 0.00129, saving model to best.weights.h5 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 82s 49ms/step - fashion_mnist_out_loss: 7.9070e-04 - fashion_mnist_out_mse: 7.9070e-04 - loss: 0.0014 - mnist_out_loss: 6.5406e-04 - mnist_out_mse: 6.5406e-04 - val_fashion_mnist_out_loss: 6.6011e-04 - val_fashion_mnist_out_mse: 6.6011e-04 - val_loss: 0.0013 - val_mnist_out_loss: 6.3111e-04 - val_mnist_out_mse: 6.3111e-04 - learning_rate: 0.0010 Epoch 12/150 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 0s 33ms/step - fashion_mnist_out_loss: 7.9189e-04 - fashion_mnist_out_mse: 7.9189e-04 - loss: 0.0015 - mnist_out_loss: 6.6165e-04 - mnist_out_mse: 6.6165e-04 Epoch 12: val_loss improved from 0.00129 to 0.00122, saving model to best.weights.h5 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 58s 34ms/step - fashion_mnist_out_loss: 7.9188e-04 - fashion_mnist_out_mse: 7.9188e-04 - loss: 0.0015 - mnist_out_loss: 6.6164e-04 - mnist_out_mse: 6.6164e-04 - val_fashion_mnist_out_loss: 6.2553e-04 - val_fashion_mnist_out_mse: 6.2553e-04 - val_loss: 0.0012 - val_mnist_out_loss: 5.9899e-04 - val_mnist_out_mse: 5.9899e-04 - learning_rate: 0.0010 Epoch 13/150 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 0s 33ms/step - fashion_mnist_out_loss: 7.6317e-04 - fashion_mnist_out_mse: 7.6317e-04 - loss: 0.0014 - mnist_out_loss: 6.4513e-04 - mnist_out_mse: 6.4513e-04 Epoch 13: val_loss did not improve from 0.00122 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 82s 48ms/step - fashion_mnist_out_loss: 7.6316e-04 - fashion_mnist_out_mse: 7.6316e-04 - loss: 0.0014 - mnist_out_loss: 6.4512e-04 - mnist_out_mse: 6.4512e-04 - val_fashion_mnist_out_loss: 6.5299e-04 - val_fashion_mnist_out_mse: 6.5299e-04 - val_loss: 0.0012 - val_mnist_out_loss: 5.9352e-04 - val_mnist_out_mse: 5.9352e-04 - learning_rate: 0.0010 Epoch 14/150 1686/1687 ━━━━━━━━━━━━━━━━━━━━ 0s 33ms/step - fashion_mnist_out_loss: 7.4198e-04 - fashion_mnist_out_mse: 7.4198e-04 - loss: 0.0014 - mnist_out_loss: 6.1201e-04 - mnist_out_mse: 6.1201e-04 Epoch 14: val_loss did not improve from 0.00122 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 82s 49ms/step - fashion_mnist_out_loss: 7.4197e-04 - fashion_mnist_out_mse: 7.4197e-04 - loss: 0.0014 - mnist_out_loss: 6.1201e-04 - mnist_out_mse: 6.1202e-04 - val_fashion_mnist_out_loss: 7.2454e-04 - val_fashion_mnist_out_mse: 7.2454e-04 - val_loss: 0.0014 - val_mnist_out_loss: 6.6879e-04 - val_mnist_out_mse: 6.6879e-04 - learning_rate: 0.0010 Epoch 15/150 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 0s 33ms/step - fashion_mnist_out_loss: 7.0332e-04 - fashion_mnist_out_mse: 7.0332e-04 - loss: 0.0013 - mnist_out_loss: 5.9489e-04 - mnist_out_mse: 5.9489e-04 Epoch 15: val_loss did not improve from 0.00122 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 58s 34ms/step - fashion_mnist_out_loss: 7.0332e-04 - fashion_mnist_out_mse: 7.0332e-04 - loss: 0.0013 - mnist_out_loss: 5.9489e-04 - mnist_out_mse: 5.9489e-04 - val_fashion_mnist_out_loss: 7.4257e-04 - val_fashion_mnist_out_mse: 7.4257e-04 - val_loss: 0.0013 - val_mnist_out_loss: 5.5967e-04 - val_mnist_out_mse: 5.5967e-04 - learning_rate: 0.0010 Epoch 16/150 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 0s 33ms/step - fashion_mnist_out_loss: 6.8581e-04 - fashion_mnist_out_mse: 6.8581e-04 - loss: 0.0013 - mnist_out_loss: 5.8305e-04 - mnist_out_mse: 5.8305e-04 Epoch 16: val_loss did not improve from 0.00122 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 57s 34ms/step - fashion_mnist_out_loss: 6.8581e-04 - fashion_mnist_out_mse: 6.8581e-04 - loss: 0.0013 - mnist_out_loss: 5.8305e-04 - mnist_out_mse: 5.8305e-04 - val_fashion_mnist_out_loss: 7.3047e-04 - val_fashion_mnist_out_mse: 7.3047e-04 - val_loss: 0.0013 - val_mnist_out_loss: 5.8567e-04 - val_mnist_out_mse: 5.8567e-04 - learning_rate: 0.0010 Epoch 17/150 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 0s 33ms/step - fashion_mnist_out_loss: 6.6746e-04 - fashion_mnist_out_mse: 6.6746e-04 - loss: 0.0012 - mnist_out_loss: 5.7188e-04 - mnist_out_mse: 5.7188e-04 Epoch 17: val_loss improved from 0.00122 to 0.00121, saving model to best.weights.h5 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 58s 34ms/step - fashion_mnist_out_loss: 6.6747e-04 - fashion_mnist_out_mse: 6.6747e-04 - loss: 0.0012 - mnist_out_loss: 5.7188e-04 - mnist_out_mse: 5.7188e-04 - val_fashion_mnist_out_loss: 6.2585e-04 - val_fashion_mnist_out_mse: 6.2585e-04 - val_loss: 0.0012 - val_mnist_out_loss: 5.8320e-04 - val_mnist_out_mse: 5.8320e-04 - learning_rate: 0.0010 Epoch 18/150 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 0s 33ms/step - fashion_mnist_out_loss: 6.7039e-04 - fashion_mnist_out_mse: 6.7039e-04 - loss: 0.0012 - mnist_out_loss: 5.6225e-04 - mnist_out_mse: 5.6225e-04 Epoch 18: val_loss did not improve from 0.00121 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 58s 34ms/step - fashion_mnist_out_loss: 6.7039e-04 - fashion_mnist_out_mse: 6.7039e-04 - loss: 0.0012 - mnist_out_loss: 5.6224e-04 - mnist_out_mse: 5.6224e-04 - val_fashion_mnist_out_loss: 7.6562e-04 - val_fashion_mnist_out_mse: 7.6562e-04 - val_loss: 0.0013 - val_mnist_out_loss: 5.5241e-04 - val_mnist_out_mse: 5.5241e-04 - learning_rate: 0.0010 Epoch 19/150 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 0s 33ms/step - fashion_mnist_out_loss: 6.2433e-04 - fashion_mnist_out_mse: 6.2433e-04 - loss: 0.0012 - mnist_out_loss: 5.4251e-04 - mnist_out_mse: 5.4251e-04 Epoch 19: val_loss improved from 0.00121 to 0.00112, saving model to best.weights.h5 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 58s 35ms/step - fashion_mnist_out_loss: 6.2434e-04 - fashion_mnist_out_mse: 6.2434e-04 - loss: 0.0012 - mnist_out_loss: 5.4251e-04 - mnist_out_mse: 5.4251e-04 - val_fashion_mnist_out_loss: 5.7344e-04 - val_fashion_mnist_out_mse: 5.7344e-04 - val_loss: 0.0011 - val_mnist_out_loss: 5.4231e-04 - val_mnist_out_mse: 5.4231e-04 - learning_rate: 0.0010 Epoch 20/150 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 0s 33ms/step - fashion_mnist_out_loss: 6.2475e-04 - fashion_mnist_out_mse: 6.2475e-04 - loss: 0.0012 - mnist_out_loss: 5.3250e-04 - mnist_out_mse: 5.3250e-04 Epoch 20: val_loss did not improve from 0.00112 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 82s 48ms/step - fashion_mnist_out_loss: 6.2476e-04 - fashion_mnist_out_mse: 6.2476e-04 - loss: 0.0012 - mnist_out_loss: 5.3250e-04 - mnist_out_mse: 5.3250e-04 - val_fashion_mnist_out_loss: 6.5094e-04 - val_fashion_mnist_out_mse: 6.5094e-04 - val_loss: 0.0012 - val_mnist_out_loss: 5.9051e-04 - val_mnist_out_mse: 5.9051e-04 - learning_rate: 0.0010 Epoch 21/150 1686/1687 ━━━━━━━━━━━━━━━━━━━━ 0s 33ms/step - fashion_mnist_out_loss: 6.1711e-04 - fashion_mnist_out_mse: 6.1711e-04 - loss: 0.0012 - mnist_out_loss: 5.3349e-04 - mnist_out_mse: 5.3349e-04 Epoch 21: val_loss improved from 0.00112 to 0.00103, saving model to best.weights.h5 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 59s 35ms/step - fashion_mnist_out_loss: 6.1710e-04 - fashion_mnist_out_mse: 6.1710e-04 - loss: 0.0012 - mnist_out_loss: 5.3348e-04 - mnist_out_mse: 5.3348e-04 - val_fashion_mnist_out_loss: 5.2535e-04 - val_fashion_mnist_out_mse: 5.2535e-04 - val_loss: 0.0010 - val_mnist_out_loss: 5.0611e-04 - val_mnist_out_mse: 5.0611e-04 - learning_rate: 0.0010 Epoch 22/150 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 0s 33ms/step - fashion_mnist_out_loss: 6.0919e-04 - fashion_mnist_out_mse: 6.0919e-04 - loss: 0.0011 - mnist_out_loss: 5.3169e-04 - mnist_out_mse: 5.3169e-04 Epoch 22: val_loss did not improve from 0.00103 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 58s 35ms/step - fashion_mnist_out_loss: 6.0920e-04 - fashion_mnist_out_mse: 6.0920e-04 - loss: 0.0011 - mnist_out_loss: 5.3169e-04 - mnist_out_mse: 5.3169e-04 - val_fashion_mnist_out_loss: 5.5932e-04 - val_fashion_mnist_out_mse: 5.5932e-04 - val_loss: 0.0011 - val_mnist_out_loss: 5.1028e-04 - val_mnist_out_mse: 5.1028e-04 - learning_rate: 0.0010 Epoch 23/150 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 0s 33ms/step - fashion_mnist_out_loss: 5.8630e-04 - fashion_mnist_out_mse: 5.8630e-04 - loss: 0.0011 - mnist_out_loss: 5.1032e-04 - mnist_out_mse: 5.1032e-04 Epoch 23: val_loss did not improve from 0.00103 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 82s 49ms/step - fashion_mnist_out_loss: 5.8630e-04 - fashion_mnist_out_mse: 5.8630e-04 - loss: 0.0011 - mnist_out_loss: 5.1032e-04 - mnist_out_mse: 5.1032e-04 - val_fashion_mnist_out_loss: 5.4154e-04 - val_fashion_mnist_out_mse: 5.4154e-04 - val_loss: 0.0010 - val_mnist_out_loss: 4.9473e-04 - val_mnist_out_mse: 4.9473e-04 - learning_rate: 0.0010 Epoch 24/150 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 0s 33ms/step - fashion_mnist_out_loss: 5.8527e-04 - fashion_mnist_out_mse: 5.8527e-04 - loss: 0.0011 - mnist_out_loss: 5.1054e-04 - mnist_out_mse: 5.1054e-04 Epoch 24: val_loss did not improve from 0.00103 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 58s 34ms/step - fashion_mnist_out_loss: 5.8528e-04 - fashion_mnist_out_mse: 5.8528e-04 - loss: 0.0011 - mnist_out_loss: 5.1054e-04 - mnist_out_mse: 5.1054e-04 - val_fashion_mnist_out_loss: 5.3878e-04 - val_fashion_mnist_out_mse: 5.3878e-04 - val_loss: 0.0010 - val_mnist_out_loss: 5.0258e-04 - val_mnist_out_mse: 5.0258e-04 - learning_rate: 0.0010 Epoch 25/150 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 0s 33ms/step - fashion_mnist_out_loss: 5.7152e-04 - fashion_mnist_out_mse: 5.7152e-04 - loss: 0.0011 - mnist_out_loss: 5.0040e-04 - mnist_out_mse: 5.0040e-04 Epoch 25: val_loss did not improve from 0.00103 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 82s 49ms/step - fashion_mnist_out_loss: 5.7151e-04 - fashion_mnist_out_mse: 5.7151e-04 - loss: 0.0011 - mnist_out_loss: 5.0040e-04 - mnist_out_mse: 5.0040e-04 - val_fashion_mnist_out_loss: 5.9720e-04 - val_fashion_mnist_out_mse: 5.9720e-04 - val_loss: 0.0011 - val_mnist_out_loss: 5.0257e-04 - val_mnist_out_mse: 5.0257e-04 - learning_rate: 0.0010 Epoch 26/150 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 0s 33ms/step - fashion_mnist_out_loss: 5.7619e-04 - fashion_mnist_out_mse: 5.7619e-04 - loss: 0.0011 - mnist_out_loss: 4.9936e-04 - mnist_out_mse: 4.9936e-04 Epoch 26: val_loss did not improve from 0.00103 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 58s 34ms/step - fashion_mnist_out_loss: 5.7619e-04 - fashion_mnist_out_mse: 5.7619e-04 - loss: 0.0011 - mnist_out_loss: 4.9936e-04 - mnist_out_mse: 4.9936e-04 - val_fashion_mnist_out_loss: 5.4635e-04 - val_fashion_mnist_out_mse: 5.4635e-04 - val_loss: 0.0010 - val_mnist_out_loss: 4.8895e-04 - val_mnist_out_mse: 4.8895e-04 - learning_rate: 0.0010 Epoch 27/150 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 0s 33ms/step - fashion_mnist_out_loss: 5.6009e-04 - fashion_mnist_out_mse: 5.6009e-04 - loss: 0.0011 - mnist_out_loss: 4.9057e-04 - mnist_out_mse: 4.9057e-04 Epoch 27: val_loss improved from 0.00103 to 0.00096, saving model to best.weights.h5 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 82s 49ms/step - fashion_mnist_out_loss: 5.6009e-04 - fashion_mnist_out_mse: 5.6009e-04 - loss: 0.0011 - mnist_out_loss: 4.9057e-04 - mnist_out_mse: 4.9057e-04 - val_fashion_mnist_out_loss: 4.9086e-04 - val_fashion_mnist_out_mse: 4.9086e-04 - val_loss: 9.6391e-04 - val_mnist_out_loss: 4.7304e-04 - val_mnist_out_mse: 4.7304e-04 - learning_rate: 0.0010 Epoch 28/150 1686/1687 ━━━━━━━━━━━━━━━━━━━━ 0s 33ms/step - fashion_mnist_out_loss: 5.5170e-04 - fashion_mnist_out_mse: 5.5170e-04 - loss: 0.0010 - mnist_out_loss: 4.8821e-04 - mnist_out_mse: 4.8821e-04 Epoch 28: val_loss did not improve from 0.00096 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 58s 34ms/step - fashion_mnist_out_loss: 5.5169e-04 - fashion_mnist_out_mse: 5.5169e-04 - loss: 0.0010 - mnist_out_loss: 4.8821e-04 - mnist_out_mse: 4.8821e-04 - val_fashion_mnist_out_loss: 5.0674e-04 - val_fashion_mnist_out_mse: 5.0674e-04 - val_loss: 9.8622e-04 - val_mnist_out_loss: 4.7948e-04 - val_mnist_out_mse: 4.7948e-04 - learning_rate: 0.0010 Epoch 29/150 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 0s 34ms/step - fashion_mnist_out_loss: 5.4385e-04 - fashion_mnist_out_mse: 5.4385e-04 - loss: 0.0010 - mnist_out_loss: 4.8725e-04 - mnist_out_mse: 4.8725e-04 Epoch 29: val_loss did not improve from 0.00096 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 82s 49ms/step - fashion_mnist_out_loss: 5.4385e-04 - fashion_mnist_out_mse: 5.4385e-04 - loss: 0.0010 - mnist_out_loss: 4.8726e-04 - mnist_out_mse: 4.8726e-04 - val_fashion_mnist_out_loss: 5.2722e-04 - val_fashion_mnist_out_mse: 5.2722e-04 - val_loss: 0.0010 - val_mnist_out_loss: 4.8360e-04 - val_mnist_out_mse: 4.8360e-04 - learning_rate: 0.0010 Epoch 30/150 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 0s 33ms/step - fashion_mnist_out_loss: 5.3226e-04 - fashion_mnist_out_mse: 5.3226e-04 - loss: 0.0010 - mnist_out_loss: 4.7701e-04 - mnist_out_mse: 4.7701e-04 Epoch 30: val_loss did not improve from 0.00096 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 58s 35ms/step - fashion_mnist_out_loss: 5.3226e-04 - fashion_mnist_out_mse: 5.3226e-04 - loss: 0.0010 - mnist_out_loss: 4.7701e-04 - mnist_out_mse: 4.7701e-04 - val_fashion_mnist_out_loss: 5.1739e-04 - val_fashion_mnist_out_mse: 5.1739e-04 - val_loss: 9.8192e-04 - val_mnist_out_loss: 4.6453e-04 - val_mnist_out_mse: 4.6453e-04 - learning_rate: 0.0010 Epoch 31/150 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 0s 33ms/step - fashion_mnist_out_loss: 5.3194e-04 - fashion_mnist_out_mse: 5.3194e-04 - loss: 0.0010 - mnist_out_loss: 4.7514e-04 - mnist_out_mse: 4.7514e-04 Epoch 31: val_loss improved from 0.00096 to 0.00096, saving model to best.weights.h5 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 82s 49ms/step - fashion_mnist_out_loss: 5.3194e-04 - fashion_mnist_out_mse: 5.3194e-04 - loss: 0.0010 - mnist_out_loss: 4.7514e-04 - mnist_out_mse: 4.7514e-04 - val_fashion_mnist_out_loss: 4.9698e-04 - val_fashion_mnist_out_mse: 4.9698e-04 - val_loss: 9.5935e-04 - val_mnist_out_loss: 4.6237e-04 - val_mnist_out_mse: 4.6237e-04 - learning_rate: 0.0010 Epoch 32/150 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 0s 33ms/step - fashion_mnist_out_loss: 5.2316e-04 - fashion_mnist_out_mse: 5.2316e-04 - loss: 9.8791e-04 - mnist_out_loss: 4.6475e-04 - mnist_out_mse: 4.6475e-04 Epoch 32: val_loss improved from 0.00096 to 0.00096, saving model to best.weights.h5 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 82s 49ms/step - fashion_mnist_out_loss: 5.2316e-04 - fashion_mnist_out_mse: 5.2316e-04 - loss: 9.8791e-04 - mnist_out_loss: 4.6475e-04 - mnist_out_mse: 4.6475e-04 - val_fashion_mnist_out_loss: 4.9741e-04 - val_fashion_mnist_out_mse: 4.9741e-04 - val_loss: 9.5816e-04 - val_mnist_out_loss: 4.6075e-04 - val_mnist_out_mse: 4.6075e-04 - learning_rate: 0.0010 Epoch 33/150 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 0s 34ms/step - fashion_mnist_out_loss: 5.1175e-04 - fashion_mnist_out_mse: 5.1175e-04 - loss: 9.7325e-04 - mnist_out_loss: 4.6149e-04 - mnist_out_mse: 4.6149e-04 Epoch 33: val_loss improved from 0.00096 to 0.00095, saving model to best.weights.h5 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 82s 48ms/step - fashion_mnist_out_loss: 5.1176e-04 - fashion_mnist_out_mse: 5.1176e-04 - loss: 9.7325e-04 - mnist_out_loss: 4.6149e-04 - mnist_out_mse: 4.6149e-04 - val_fashion_mnist_out_loss: 4.9350e-04 - val_fashion_mnist_out_mse: 4.9350e-04 - val_loss: 9.4829e-04 - val_mnist_out_loss: 4.5479e-04 - val_mnist_out_mse: 4.5479e-04 - learning_rate: 0.0010 Epoch 34/150 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 0s 33ms/step - fashion_mnist_out_loss: 5.1522e-04 - fashion_mnist_out_mse: 5.1522e-04 - loss: 9.7738e-04 - mnist_out_loss: 4.6217e-04 - mnist_out_mse: 4.6217e-04 Epoch 34: val_loss did not improve from 0.00095 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 82s 48ms/step - fashion_mnist_out_loss: 5.1521e-04 - fashion_mnist_out_mse: 5.1521e-04 - loss: 9.7738e-04 - mnist_out_loss: 4.6216e-04 - mnist_out_mse: 4.6216e-04 - val_fashion_mnist_out_loss: 5.1088e-04 - val_fashion_mnist_out_mse: 5.1088e-04 - val_loss: 9.7218e-04 - val_mnist_out_loss: 4.6130e-04 - val_mnist_out_mse: 4.6130e-04 - learning_rate: 0.0010 Epoch 35/150 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 0s 34ms/step - fashion_mnist_out_loss: 5.0913e-04 - fashion_mnist_out_mse: 5.0913e-04 - loss: 9.7081e-04 - mnist_out_loss: 4.6168e-04 - mnist_out_mse: 4.6168e-04 Epoch 35: ReduceLROnPlateau reducing learning rate to 0.0003000000142492354. Epoch 35: val_loss improved from 0.00095 to 0.00089, saving model to best.weights.h5 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 82s 49ms/step - fashion_mnist_out_loss: 5.0913e-04 - fashion_mnist_out_mse: 5.0913e-04 - loss: 9.7081e-04 - mnist_out_loss: 4.6168e-04 - mnist_out_mse: 4.6168e-04 - val_fashion_mnist_out_loss: 4.5452e-04 - val_fashion_mnist_out_mse: 4.5452e-04 - val_loss: 8.9221e-04 - val_mnist_out_loss: 4.3769e-04 - val_mnist_out_mse: 4.3769e-04 - learning_rate: 0.0010 Epoch 36/150 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 0s 33ms/step - fashion_mnist_out_loss: 4.5384e-04 - fashion_mnist_out_mse: 4.5384e-04 - loss: 8.8205e-04 - mnist_out_loss: 4.2821e-04 - mnist_out_mse: 4.2821e-04 Epoch 36: val_loss improved from 0.00089 to 0.00082, saving model to best.weights.h5 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 59s 35ms/step - fashion_mnist_out_loss: 4.5383e-04 - fashion_mnist_out_mse: 4.5383e-04 - loss: 8.8205e-04 - mnist_out_loss: 4.2821e-04 - mnist_out_mse: 4.2821e-04 - val_fashion_mnist_out_loss: 4.1841e-04 - val_fashion_mnist_out_mse: 4.1841e-04 - val_loss: 8.2445e-04 - val_mnist_out_loss: 4.0604e-04 - val_mnist_out_mse: 4.0604e-04 - learning_rate: 3.0000e-04 Epoch 37/150 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 0s 33ms/step - fashion_mnist_out_loss: 4.4709e-04 - fashion_mnist_out_mse: 4.4709e-04 - loss: 8.6869e-04 - mnist_out_loss: 4.2160e-04 - mnist_out_mse: 4.2160e-04 Epoch 37: val_loss did not improve from 0.00082 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 59s 35ms/step - fashion_mnist_out_loss: 4.4709e-04 - fashion_mnist_out_mse: 4.4709e-04 - loss: 8.6869e-04 - mnist_out_loss: 4.2160e-04 - mnist_out_mse: 4.2160e-04 - val_fashion_mnist_out_loss: 4.2422e-04 - val_fashion_mnist_out_mse: 4.2422e-04 - val_loss: 8.3679e-04 - val_mnist_out_loss: 4.1257e-04 - val_mnist_out_mse: 4.1257e-04 - learning_rate: 3.0000e-04 Epoch 38/150 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 0s 34ms/step - fashion_mnist_out_loss: 4.3706e-04 - fashion_mnist_out_mse: 4.3706e-04 - loss: 8.5031e-04 - mnist_out_loss: 4.1325e-04 - mnist_out_mse: 4.1325e-04 Epoch 38: val_loss did not improve from 0.00082 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 59s 35ms/step - fashion_mnist_out_loss: 4.3706e-04 - fashion_mnist_out_mse: 4.3706e-04 - loss: 8.5031e-04 - mnist_out_loss: 4.1325e-04 - mnist_out_mse: 4.1325e-04 - val_fashion_mnist_out_loss: 4.7615e-04 - val_fashion_mnist_out_mse: 4.7615e-04 - val_loss: 8.9123e-04 - val_mnist_out_loss: 4.1508e-04 - val_mnist_out_mse: 4.1508e-04 - learning_rate: 3.0000e-04 Epoch 39/150 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 0s 34ms/step - fashion_mnist_out_loss: 4.4333e-04 - fashion_mnist_out_mse: 4.4333e-04 - loss: 8.6008e-04 - mnist_out_loss: 4.1675e-04 - mnist_out_mse: 4.1675e-04 Epoch 39: val_loss improved from 0.00082 to 0.00081, saving model to best.weights.h5 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 60s 35ms/step - fashion_mnist_out_loss: 4.4332e-04 - fashion_mnist_out_mse: 4.4332e-04 - loss: 8.6007e-04 - mnist_out_loss: 4.1675e-04 - mnist_out_mse: 4.1675e-04 - val_fashion_mnist_out_loss: 4.1088e-04 - val_fashion_mnist_out_mse: 4.1088e-04 - val_loss: 8.1205e-04 - val_mnist_out_loss: 4.0117e-04 - val_mnist_out_mse: 4.0117e-04 - learning_rate: 3.0000e-04 Epoch 40/150 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 0s 34ms/step - fashion_mnist_out_loss: 4.3717e-04 - fashion_mnist_out_mse: 4.3717e-04 - loss: 8.4996e-04 - mnist_out_loss: 4.1279e-04 - mnist_out_mse: 4.1279e-04 Epoch 40: val_loss did not improve from 0.00081 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 59s 35ms/step - fashion_mnist_out_loss: 4.3716e-04 - fashion_mnist_out_mse: 4.3716e-04 - loss: 8.4995e-04 - mnist_out_loss: 4.1279e-04 - mnist_out_mse: 4.1279e-04 - val_fashion_mnist_out_loss: 4.1557e-04 - val_fashion_mnist_out_mse: 4.1557e-04 - val_loss: 8.1949e-04 - val_mnist_out_loss: 4.0392e-04 - val_mnist_out_mse: 4.0392e-04 - learning_rate: 3.0000e-04 Epoch 41/150 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 0s 34ms/step - fashion_mnist_out_loss: 4.3270e-04 - fashion_mnist_out_mse: 4.3270e-04 - loss: 8.4246e-04 - mnist_out_loss: 4.0976e-04 - mnist_out_mse: 4.0976e-04 Epoch 41: val_loss did not improve from 0.00081 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 59s 35ms/step - fashion_mnist_out_loss: 4.3270e-04 - fashion_mnist_out_mse: 4.3270e-04 - loss: 8.4246e-04 - mnist_out_loss: 4.0976e-04 - mnist_out_mse: 4.0976e-04 - val_fashion_mnist_out_loss: 4.1541e-04 - val_fashion_mnist_out_mse: 4.1541e-04 - val_loss: 8.1509e-04 - val_mnist_out_loss: 3.9968e-04 - val_mnist_out_mse: 3.9968e-04 - learning_rate: 3.0000e-04 Epoch 42/150 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 0s 34ms/step - fashion_mnist_out_loss: 4.3016e-04 - fashion_mnist_out_mse: 4.3016e-04 - loss: 8.3786e-04 - mnist_out_loss: 4.0770e-04 - mnist_out_mse: 4.0770e-04 Epoch 42: val_loss did not improve from 0.00081 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 82s 49ms/step - fashion_mnist_out_loss: 4.3016e-04 - fashion_mnist_out_mse: 4.3016e-04 - loss: 8.3786e-04 - mnist_out_loss: 4.0770e-04 - mnist_out_mse: 4.0770e-04 - val_fashion_mnist_out_loss: 4.1505e-04 - val_fashion_mnist_out_mse: 4.1505e-04 - val_loss: 8.2039e-04 - val_mnist_out_loss: 4.0534e-04 - val_mnist_out_mse: 4.0534e-04 - learning_rate: 3.0000e-04 Epoch 43/150 1686/1687 ━━━━━━━━━━━━━━━━━━━━ 0s 34ms/step - fashion_mnist_out_loss: 4.3403e-04 - fashion_mnist_out_mse: 4.3403e-04 - loss: 8.4605e-04 - mnist_out_loss: 4.1202e-04 - mnist_out_mse: 4.1202e-04 Epoch 43: val_loss improved from 0.00081 to 0.00081, saving model to best.weights.h5 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 60s 36ms/step - fashion_mnist_out_loss: 4.3403e-04 - fashion_mnist_out_mse: 4.3403e-04 - loss: 8.4604e-04 - mnist_out_loss: 4.1201e-04 - mnist_out_mse: 4.1201e-04 - val_fashion_mnist_out_loss: 4.2068e-04 - val_fashion_mnist_out_mse: 4.2068e-04 - val_loss: 8.0691e-04 - val_mnist_out_loss: 3.8623e-04 - val_mnist_out_mse: 3.8623e-04 - learning_rate: 3.0000e-04 Epoch 44/150 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 0s 34ms/step - fashion_mnist_out_loss: 4.2365e-04 - fashion_mnist_out_mse: 4.2365e-04 - loss: 8.2559e-04 - mnist_out_loss: 4.0194e-04 - mnist_out_mse: 4.0194e-04 Epoch 44: ReduceLROnPlateau reducing learning rate to 9.000000427477062e-05. Epoch 44: val_loss improved from 0.00081 to 0.00080, saving model to best.weights.h5 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 60s 35ms/step - fashion_mnist_out_loss: 4.2365e-04 - fashion_mnist_out_mse: 4.2365e-04 - loss: 8.2559e-04 - mnist_out_loss: 4.0194e-04 - mnist_out_mse: 4.0194e-04 - val_fashion_mnist_out_loss: 4.0503e-04 - val_fashion_mnist_out_mse: 4.0503e-04 - val_loss: 8.0223e-04 - val_mnist_out_loss: 3.9721e-04 - val_mnist_out_mse: 3.9721e-04 - learning_rate: 3.0000e-04 Epoch 45/150 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 0s 34ms/step - fashion_mnist_out_loss: 4.1853e-04 - fashion_mnist_out_mse: 4.1853e-04 - loss: 8.1943e-04 - mnist_out_loss: 4.0090e-04 - mnist_out_mse: 4.0090e-04 Epoch 45: val_loss improved from 0.00080 to 0.00077, saving model to best.weights.h5 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 60s 35ms/step - fashion_mnist_out_loss: 4.1853e-04 - fashion_mnist_out_mse: 4.1853e-04 - loss: 8.1943e-04 - mnist_out_loss: 4.0090e-04 - mnist_out_mse: 4.0090e-04 - val_fashion_mnist_out_loss: 3.9162e-04 - val_fashion_mnist_out_mse: 3.9162e-04 - val_loss: 7.7114e-04 - val_mnist_out_loss: 3.7952e-04 - val_mnist_out_mse: 3.7952e-04 - learning_rate: 9.0000e-05 Epoch 46/150 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 0s 34ms/step - fashion_mnist_out_loss: 4.0992e-04 - fashion_mnist_out_mse: 4.0992e-04 - loss: 8.0391e-04 - mnist_out_loss: 3.9399e-04 - mnist_out_mse: 3.9399e-04 Epoch 46: val_loss did not improve from 0.00077 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 59s 35ms/step - fashion_mnist_out_loss: 4.0992e-04 - fashion_mnist_out_mse: 4.0992e-04 - loss: 8.0391e-04 - mnist_out_loss: 3.9399e-04 - mnist_out_mse: 3.9399e-04 - val_fashion_mnist_out_loss: 3.9569e-04 - val_fashion_mnist_out_mse: 3.9569e-04 - val_loss: 7.8137e-04 - val_mnist_out_loss: 3.8568e-04 - val_mnist_out_mse: 3.8568e-04 - learning_rate: 9.0000e-05 Epoch 47/150 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 0s 34ms/step - fashion_mnist_out_loss: 4.0927e-04 - fashion_mnist_out_mse: 4.0927e-04 - loss: 8.0070e-04 - mnist_out_loss: 3.9144e-04 - mnist_out_mse: 3.9144e-04 Epoch 47: val_loss did not improve from 0.00077 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 82s 49ms/step - fashion_mnist_out_loss: 4.0926e-04 - fashion_mnist_out_mse: 4.0926e-04 - loss: 8.0070e-04 - mnist_out_loss: 3.9144e-04 - mnist_out_mse: 3.9144e-04 - val_fashion_mnist_out_loss: 4.0422e-04 - val_fashion_mnist_out_mse: 4.0422e-04 - val_loss: 7.9458e-04 - val_mnist_out_loss: 3.9035e-04 - val_mnist_out_mse: 3.9035e-04 - learning_rate: 9.0000e-05 Epoch 48/150 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 0s 34ms/step - fashion_mnist_out_loss: 4.0893e-04 - fashion_mnist_out_mse: 4.0893e-04 - loss: 8.0147e-04 - mnist_out_loss: 3.9254e-04 - mnist_out_mse: 3.9254e-04 Epoch 48: val_loss did not improve from 0.00077 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 82s 49ms/step - fashion_mnist_out_loss: 4.0893e-04 - fashion_mnist_out_mse: 4.0893e-04 - loss: 8.0147e-04 - mnist_out_loss: 3.9254e-04 - mnist_out_mse: 3.9254e-04 - val_fashion_mnist_out_loss: 4.0066e-04 - val_fashion_mnist_out_mse: 4.0066e-04 - val_loss: 7.9275e-04 - val_mnist_out_loss: 3.9209e-04 - val_mnist_out_mse: 3.9209e-04 - learning_rate: 9.0000e-05 Epoch 49/150 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 0s 34ms/step - fashion_mnist_out_loss: 4.0763e-04 - fashion_mnist_out_mse: 4.0763e-04 - loss: 7.9874e-04 - mnist_out_loss: 3.9111e-04 - mnist_out_mse: 3.9111e-04 Epoch 49: val_loss did not improve from 0.00077 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 60s 35ms/step - fashion_mnist_out_loss: 4.0763e-04 - fashion_mnist_out_mse: 4.0763e-04 - loss: 7.9874e-04 - mnist_out_loss: 3.9111e-04 - mnist_out_mse: 3.9111e-04 - val_fashion_mnist_out_loss: 4.0080e-04 - val_fashion_mnist_out_mse: 4.0080e-04 - val_loss: 7.9291e-04 - val_mnist_out_loss: 3.9211e-04 - val_mnist_out_mse: 3.9211e-04 - learning_rate: 9.0000e-05 Epoch 50/150 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 0s 34ms/step - fashion_mnist_out_loss: 4.1125e-04 - fashion_mnist_out_mse: 4.1125e-04 - loss: 8.0673e-04 - mnist_out_loss: 3.9548e-04 - mnist_out_mse: 3.9548e-04 Epoch 50: val_loss did not improve from 0.00077 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 82s 49ms/step - fashion_mnist_out_loss: 4.1125e-04 - fashion_mnist_out_mse: 4.1125e-04 - loss: 8.0673e-04 - mnist_out_loss: 3.9548e-04 - mnist_out_mse: 3.9548e-04 - val_fashion_mnist_out_loss: 3.9803e-04 - val_fashion_mnist_out_mse: 3.9803e-04 - val_loss: 7.8547e-04 - val_mnist_out_loss: 3.8744e-04 - val_mnist_out_mse: 3.8744e-04 - learning_rate: 9.0000e-05 Epoch 51/150 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 0s 34ms/step - fashion_mnist_out_loss: 4.0548e-04 - fashion_mnist_out_mse: 4.0548e-04 - loss: 7.9411e-04 - mnist_out_loss: 3.8863e-04 - mnist_out_mse: 3.8863e-04 Epoch 51: val_loss did not improve from 0.00077 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 82s 49ms/step - fashion_mnist_out_loss: 4.0548e-04 - fashion_mnist_out_mse: 4.0548e-04 - loss: 7.9411e-04 - mnist_out_loss: 3.8863e-04 - mnist_out_mse: 3.8863e-04 - val_fashion_mnist_out_loss: 3.9309e-04 - val_fashion_mnist_out_mse: 3.9309e-04 - val_loss: 7.7732e-04 - val_mnist_out_loss: 3.8422e-04 - val_mnist_out_mse: 3.8422e-04 - learning_rate: 9.0000e-05 Epoch 52/150 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 0s 34ms/step - fashion_mnist_out_loss: 4.0022e-04 - fashion_mnist_out_mse: 4.0022e-04 - loss: 7.8553e-04 - mnist_out_loss: 3.8531e-04 - mnist_out_mse: 3.8531e-04 Epoch 52: ReduceLROnPlateau reducing learning rate to 2.700000040931627e-05. Epoch 52: val_loss did not improve from 0.00077 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 82s 49ms/step - fashion_mnist_out_loss: 4.0022e-04 - fashion_mnist_out_mse: 4.0022e-04 - loss: 7.8553e-04 - mnist_out_loss: 3.8531e-04 - mnist_out_mse: 3.8531e-04 - val_fashion_mnist_out_loss: 3.9706e-04 - val_fashion_mnist_out_mse: 3.9706e-04 - val_loss: 7.8651e-04 - val_mnist_out_loss: 3.8945e-04 - val_mnist_out_mse: 3.8945e-04 - learning_rate: 9.0000e-05 Epoch 53/150 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 0s 34ms/step - fashion_mnist_out_loss: 3.9685e-04 - fashion_mnist_out_mse: 3.9685e-04 - loss: 7.7951e-04 - mnist_out_loss: 3.8266e-04 - mnist_out_mse: 3.8266e-04 Epoch 53: val_loss did not improve from 0.00077 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 82s 49ms/step - fashion_mnist_out_loss: 3.9685e-04 - fashion_mnist_out_mse: 3.9685e-04 - loss: 7.7951e-04 - mnist_out_loss: 3.8266e-04 - mnist_out_mse: 3.8266e-04 - val_fashion_mnist_out_loss: 3.9302e-04 - val_fashion_mnist_out_mse: 3.9302e-04 - val_loss: 7.7475e-04 - val_mnist_out_loss: 3.8173e-04 - val_mnist_out_mse: 3.8173e-04 - learning_rate: 2.7000e-05 Epoch 54/150 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 0s 34ms/step - fashion_mnist_out_loss: 3.9914e-04 - fashion_mnist_out_mse: 3.9914e-04 - loss: 7.8445e-04 - mnist_out_loss: 3.8531e-04 - mnist_out_mse: 3.8531e-04 Epoch 54: val_loss improved from 0.00077 to 0.00075, saving model to best.weights.h5 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 60s 36ms/step - fashion_mnist_out_loss: 3.9914e-04 - fashion_mnist_out_mse: 3.9914e-04 - loss: 7.8445e-04 - mnist_out_loss: 3.8532e-04 - mnist_out_mse: 3.8532e-04 - val_fashion_mnist_out_loss: 3.7978e-04 - val_fashion_mnist_out_mse: 3.7978e-04 - val_loss: 7.5091e-04 - val_mnist_out_loss: 3.7113e-04 - val_mnist_out_mse: 3.7113e-04 - learning_rate: 2.7000e-05 Epoch 55/150 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 0s 34ms/step - fashion_mnist_out_loss: 3.9645e-04 - fashion_mnist_out_mse: 3.9645e-04 - loss: 7.7859e-04 - mnist_out_loss: 3.8214e-04 - mnist_out_mse: 3.8214e-04 Epoch 55: val_loss did not improve from 0.00075 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 59s 35ms/step - fashion_mnist_out_loss: 3.9645e-04 - fashion_mnist_out_mse: 3.9645e-04 - loss: 7.7859e-04 - mnist_out_loss: 3.8214e-04 - mnist_out_mse: 3.8214e-04 - val_fashion_mnist_out_loss: 3.9492e-04 - val_fashion_mnist_out_mse: 3.9492e-04 - val_loss: 7.8080e-04 - val_mnist_out_loss: 3.8587e-04 - val_mnist_out_mse: 3.8587e-04 - learning_rate: 2.7000e-05 Epoch 56/150 1686/1687 ━━━━━━━━━━━━━━━━━━━━ 0s 34ms/step - fashion_mnist_out_loss: 3.9803e-04 - fashion_mnist_out_mse: 3.9803e-04 - loss: 7.8191e-04 - mnist_out_loss: 3.8388e-04 - mnist_out_mse: 3.8388e-04 Epoch 56: val_loss did not improve from 0.00075 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 60s 35ms/step - fashion_mnist_out_loss: 3.9803e-04 - fashion_mnist_out_mse: 3.9803e-04 - loss: 7.8192e-04 - mnist_out_loss: 3.8388e-04 - mnist_out_mse: 3.8388e-04 - val_fashion_mnist_out_loss: 3.9054e-04 - val_fashion_mnist_out_mse: 3.9054e-04 - val_loss: 7.7306e-04 - val_mnist_out_loss: 3.8252e-04 - val_mnist_out_mse: 3.8252e-04 - learning_rate: 2.7000e-05 Epoch 57/150 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 0s 34ms/step - fashion_mnist_out_loss: 3.9972e-04 - fashion_mnist_out_mse: 3.9972e-04 - loss: 7.8531e-04 - mnist_out_loss: 3.8559e-04 - mnist_out_mse: 3.8559e-04 Epoch 57: val_loss did not improve from 0.00075 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 60s 35ms/step - fashion_mnist_out_loss: 3.9972e-04 - fashion_mnist_out_mse: 3.9972e-04 - loss: 7.8531e-04 - mnist_out_loss: 3.8559e-04 - mnist_out_mse: 3.8559e-04 - val_fashion_mnist_out_loss: 3.8973e-04 - val_fashion_mnist_out_mse: 3.8973e-04 - val_loss: 7.6970e-04 - val_mnist_out_loss: 3.7997e-04 - val_mnist_out_mse: 3.7997e-04 - learning_rate: 2.7000e-05 Epoch 58/150 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 0s 34ms/step - fashion_mnist_out_loss: 4.0255e-04 - fashion_mnist_out_mse: 4.0255e-04 - loss: 7.9129e-04 - mnist_out_loss: 3.8874e-04 - mnist_out_mse: 3.8874e-04 Epoch 58: val_loss did not improve from 0.00075 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 82s 49ms/step - fashion_mnist_out_loss: 4.0255e-04 - fashion_mnist_out_mse: 4.0255e-04 - loss: 7.9129e-04 - mnist_out_loss: 3.8874e-04 - mnist_out_mse: 3.8874e-04 - val_fashion_mnist_out_loss: 3.9156e-04 - val_fashion_mnist_out_mse: 3.9156e-04 - val_loss: 7.7422e-04 - val_mnist_out_loss: 3.8266e-04 - val_mnist_out_mse: 3.8266e-04 - learning_rate: 2.7000e-05 Epoch 59/150 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 0s 34ms/step - fashion_mnist_out_loss: 4.0005e-04 - fashion_mnist_out_mse: 4.0005e-04 - loss: 7.8639e-04 - mnist_out_loss: 3.8633e-04 - mnist_out_mse: 3.8633e-04 Epoch 59: val_loss improved from 0.00075 to 0.00075, saving model to best.weights.h5 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 82s 49ms/step - fashion_mnist_out_loss: 4.0005e-04 - fashion_mnist_out_mse: 4.0005e-04 - loss: 7.8639e-04 - mnist_out_loss: 3.8633e-04 - mnist_out_mse: 3.8633e-04 - val_fashion_mnist_out_loss: 3.7868e-04 - val_fashion_mnist_out_mse: 3.7868e-04 - val_loss: 7.4939e-04 - val_mnist_out_loss: 3.7070e-04 - val_mnist_out_mse: 3.7070e-04 - learning_rate: 2.7000e-05 Epoch 60/150 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 0s 33ms/step - fashion_mnist_out_loss: 4.0091e-04 - fashion_mnist_out_mse: 4.0091e-04 - loss: 7.8767e-04 - mnist_out_loss: 3.8676e-04 - mnist_out_mse: 3.8676e-04 Epoch 60: ReduceLROnPlateau reducing learning rate to 1e-05. Epoch 60: val_loss did not improve from 0.00075 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 58s 35ms/step - fashion_mnist_out_loss: 4.0091e-04 - fashion_mnist_out_mse: 4.0091e-04 - loss: 7.8767e-04 - mnist_out_loss: 3.8676e-04 - mnist_out_mse: 3.8676e-04 - val_fashion_mnist_out_loss: 3.8260e-04 - val_fashion_mnist_out_mse: 3.8260e-04 - val_loss: 7.5699e-04 - val_mnist_out_loss: 3.7439e-04 - val_mnist_out_mse: 3.7439e-04 - learning_rate: 2.7000e-05 Epoch 61/150 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 0s 33ms/step - fashion_mnist_out_loss: 3.9346e-04 - fashion_mnist_out_mse: 3.9346e-04 - loss: 7.7355e-04 - mnist_out_loss: 3.8009e-04 - mnist_out_mse: 3.8009e-04 Epoch 61: val_loss did not improve from 0.00075 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 58s 35ms/step - fashion_mnist_out_loss: 3.9346e-04 - fashion_mnist_out_mse: 3.9346e-04 - loss: 7.7355e-04 - mnist_out_loss: 3.8009e-04 - mnist_out_mse: 3.8009e-04 - val_fashion_mnist_out_loss: 3.8853e-04 - val_fashion_mnist_out_mse: 3.8853e-04 - val_loss: 7.6854e-04 - val_mnist_out_loss: 3.8000e-04 - val_mnist_out_mse: 3.8000e-04 - learning_rate: 1.0000e-05 Epoch 62/150 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 0s 34ms/step - fashion_mnist_out_loss: 3.9909e-04 - fashion_mnist_out_mse: 3.9909e-04 - loss: 7.8515e-04 - mnist_out_loss: 3.8606e-04 - mnist_out_mse: 3.8606e-04 Epoch 62: val_loss did not improve from 0.00075 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 82s 49ms/step - fashion_mnist_out_loss: 3.9909e-04 - fashion_mnist_out_mse: 3.9909e-04 - loss: 7.8515e-04 - mnist_out_loss: 3.8606e-04 - mnist_out_mse: 3.8606e-04 - val_fashion_mnist_out_loss: 3.8373e-04 - val_fashion_mnist_out_mse: 3.8373e-04 - val_loss: 7.5917e-04 - val_mnist_out_loss: 3.7544e-04 - val_mnist_out_mse: 3.7544e-04 - learning_rate: 1.0000e-05 Epoch 63/150 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 0s 34ms/step - fashion_mnist_out_loss: 3.9565e-04 - fashion_mnist_out_mse: 3.9565e-04 - loss: 7.7806e-04 - mnist_out_loss: 3.8241e-04 - mnist_out_mse: 3.8241e-04 Epoch 63: val_loss did not improve from 0.00075 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 82s 48ms/step - fashion_mnist_out_loss: 3.9565e-04 - fashion_mnist_out_mse: 3.9565e-04 - loss: 7.7806e-04 - mnist_out_loss: 3.8241e-04 - mnist_out_mse: 3.8241e-04 - val_fashion_mnist_out_loss: 3.8363e-04 - val_fashion_mnist_out_mse: 3.8363e-04 - val_loss: 7.5746e-04 - val_mnist_out_loss: 3.7383e-04 - val_mnist_out_mse: 3.7383e-04 - learning_rate: 1.0000e-05 Epoch 64/150 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 0s 34ms/step - fashion_mnist_out_loss: 3.9319e-04 - fashion_mnist_out_mse: 3.9319e-04 - loss: 7.7333e-04 - mnist_out_loss: 3.8014e-04 - mnist_out_mse: 3.8014e-04 Epoch 64: val_loss did not improve from 0.00075 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 59s 35ms/step - fashion_mnist_out_loss: 3.9319e-04 - fashion_mnist_out_mse: 3.9319e-04 - loss: 7.7333e-04 - mnist_out_loss: 3.8014e-04 - mnist_out_mse: 3.8014e-04 - val_fashion_mnist_out_loss: 3.8535e-04 - val_fashion_mnist_out_mse: 3.8535e-04 - val_loss: 7.6216e-04 - val_mnist_out_loss: 3.7681e-04 - val_mnist_out_mse: 3.7681e-04 - learning_rate: 1.0000e-05 Epoch 65/150 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 0s 33ms/step - fashion_mnist_out_loss: 3.9338e-04 - fashion_mnist_out_mse: 3.9338e-04 - loss: 7.7321e-04 - mnist_out_loss: 3.7983e-04 - mnist_out_mse: 3.7983e-04 Epoch 65: val_loss did not improve from 0.00075 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 82s 49ms/step - fashion_mnist_out_loss: 3.9338e-04 - fashion_mnist_out_mse: 3.9338e-04 - loss: 7.7321e-04 - mnist_out_loss: 3.7983e-04 - mnist_out_mse: 3.7983e-04 - val_fashion_mnist_out_loss: 3.9060e-04 - val_fashion_mnist_out_mse: 3.9060e-04 - val_loss: 7.7236e-04 - val_mnist_out_loss: 3.8176e-04 - val_mnist_out_mse: 3.8176e-04 - learning_rate: 1.0000e-05 Epoch 66/150 1686/1687 ━━━━━━━━━━━━━━━━━━━━ 0s 34ms/step - fashion_mnist_out_loss: 3.9657e-04 - fashion_mnist_out_mse: 3.9657e-04 - loss: 7.7963e-04 - mnist_out_loss: 3.8305e-04 - mnist_out_mse: 3.8305e-04 Epoch 66: val_loss did not improve from 0.00075 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 59s 35ms/step - fashion_mnist_out_loss: 3.9657e-04 - fashion_mnist_out_mse: 3.9657e-04 - loss: 7.7962e-04 - mnist_out_loss: 3.8305e-04 - mnist_out_mse: 3.8305e-04 - val_fashion_mnist_out_loss: 3.8833e-04 - val_fashion_mnist_out_mse: 3.8833e-04 - val_loss: 7.6745e-04 - val_mnist_out_loss: 3.7912e-04 - val_mnist_out_mse: 3.7912e-04 - learning_rate: 1.0000e-05 Epoch 67/150 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 0s 33ms/step - fashion_mnist_out_loss: 3.9881e-04 - fashion_mnist_out_mse: 3.9881e-04 - loss: 7.8458e-04 - mnist_out_loss: 3.8577e-04 - mnist_out_mse: 3.8577e-04 Epoch 67: val_loss did not improve from 0.00075 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 82s 49ms/step - fashion_mnist_out_loss: 3.9881e-04 - fashion_mnist_out_mse: 3.9881e-04 - loss: 7.8458e-04 - mnist_out_loss: 3.8577e-04 - mnist_out_mse: 3.8577e-04 - val_fashion_mnist_out_loss: 3.8540e-04 - val_fashion_mnist_out_mse: 3.8540e-04 - val_loss: 7.6235e-04 - val_mnist_out_loss: 3.7695e-04 - val_mnist_out_mse: 3.7695e-04 - learning_rate: 1.0000e-05 Epoch 68/150 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 0s 34ms/step - fashion_mnist_out_loss: 3.9070e-04 - fashion_mnist_out_mse: 3.9070e-04 - loss: 7.6807e-04 - mnist_out_loss: 3.7737e-04 - mnist_out_mse: 3.7737e-04 Epoch 68: val_loss did not improve from 0.00075 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 82s 49ms/step - fashion_mnist_out_loss: 3.9070e-04 - fashion_mnist_out_mse: 3.9070e-04 - loss: 7.6807e-04 - mnist_out_loss: 3.7737e-04 - mnist_out_mse: 3.7737e-04 - val_fashion_mnist_out_loss: 3.8719e-04 - val_fashion_mnist_out_mse: 3.8719e-04 - val_loss: 7.6578e-04 - val_mnist_out_loss: 3.7859e-04 - val_mnist_out_mse: 3.7859e-04 - learning_rate: 1.0000e-05 Epoch 69/150 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 0s 34ms/step - fashion_mnist_out_loss: 3.9634e-04 - fashion_mnist_out_mse: 3.9634e-04 - loss: 7.7970e-04 - mnist_out_loss: 3.8337e-04 - mnist_out_mse: 3.8337e-04 Epoch 69: val_loss did not improve from 0.00075 1687/1687 ━━━━━━━━━━━━━━━━━━━━ 82s 49ms/step - fashion_mnist_out_loss: 3.9634e-04 - fashion_mnist_out_mse: 3.9634e-04 - loss: 7.7970e-04 - mnist_out_loss: 3.8337e-04 - mnist_out_mse: 3.8337e-04 - val_fashion_mnist_out_loss: 3.8428e-04 - val_fashion_mnist_out_mse: 3.8428e-04 - val_loss: 7.5992e-04 - val_mnist_out_loss: 3.7564e-04 - val_mnist_out_mse: 3.7564e-04 - learning_rate: 1.0000e-05 Epoch 69: early stopping Restoring model weights from the end of the best epoch: 59.
After 69 epochs the training stopped because of the early stop callback (10 consecutive epochs without improvement). The best epoch was the 59th and weights are saved. The learning rate reached a quite low value (1e-5) so I don't think that this kind of model could learn more than this. This is quite good because it isn't a huge model parameter-wise but it reached pretty low validation loss during training (7.5e-4) which is the sum of the two output losses.
def display_history(history):
loss_training = history.history['loss']
loss_val = history.history['val_loss']
mse_mnist_training = history.history['mnist_out_mse']
mse_mnist_val = history.history['val_mnist_out_mse']
mse_fashion_training = history.history['fashion_mnist_out_mse']
mse_fashion_val = history.history['val_fashion_mnist_out_mse']
plt.plot(loss_training)
plt.plot(loss_val)
plt.grid()
plt.title('Loss during training')
plt.xlabel('Epoch')
plt.legend(['Training', 'Validation'])
plt.show()
plt.plot(mse_fashion_training)
plt.plot(mse_fashion_val)
plt.plot(mse_mnist_training)
plt.plot(mse_mnist_val)
plt.grid()
plt.title('MSE during training')
plt.xlabel('Epoch')
plt.legend(['mse_fashion_train', 'mse_fashion_val', 'mse_mnist_train', 'mse_mnist_val'])
plt.show()
display_history(history)


The two plots above describe the training history. First of all there are no signs of overfitting.
After epoch 45 the validation loss was stable. In a 20 epoch time it just improved by 2e-5 going from 0.00077 to 0.00075. I think that to go beyond that point it is required to go way deeper with the model. Training time could increase dramatically and I don't trust Google Colab free tier GPU runtimes that much. Of course a possible way to handle that would be saving and re-loading weights but that would leave the notebook a little bit inconsistent.
Since the model outputs two predictions I decided to trace both the output losses and plot their respective values during training. This can be insightful because it tells wether was necessary or not to compute the average of the two loss functions and use it instead of the sum during training. Again, since the two losses are on the same scale I think it was fine to leave the default behaviour handled by Keras.
The first plot describes the loss during training (the sum of mnist and fashion-mnist mean squared errors). Epochs on the x-axis and loss on the y-axis. Training loss in orange and validation loss in blue.
The second plot is basically the first plot unpacked, since mnist and mnist-fashion mean squared errors progression are plotted separately.
Model evaluation¶
In order to test the model I followed the provided guidelines.
I had to reshape model's output removing the image channel to match ground truth images since they don't have the channel dimension. Mean Squared Error (MSE) is calculated for both outputs and then averaged to get the final evaluation metric.
The evaluation process is repeated 10 times to get a more reliable estimation (5000 * 10 samples in total).
The average mse obtained is 0.000388121648599426
The standard deviation is 7.954220393637751e-06. That means there is no significative variance between mse results.
testgen = datagenerator(mnist_x_test, fashion_mnist_x_test, 5000)
def eval_model(model):
x, (y1,y2) = next(testgen)
pred1,pred2 = model.predict(x)
# Remove channel to match ground truth labels
# Reshape: (5000, 32, 32, 1) -> (5000, 32, 32)
pred1 = np.squeeze(pred1, axis=-1)
pred2 = np.squeeze(pred2, axis=-1)
return (np.mean((pred1-y1)**2) + np.mean((pred2-y2)**2)) / 2
repeat_eval = 10
eval_results = []
for i in range(repeat_eval):
eval_results.append(eval_model(model))
print("mse = ", np.mean(eval_results))
print("standard deviation = ", np.std(eval_results))
157/157 ━━━━━━━━━━━━━━━━━━━━ 5s 22ms/step 157/157 ━━━━━━━━━━━━━━━━━━━━ 1s 9ms/step 157/157 ━━━━━━━━━━━━━━━━━━━━ 1s 9ms/step 157/157 ━━━━━━━━━━━━━━━━━━━━ 1s 9ms/step 157/157 ━━━━━━━━━━━━━━━━━━━━ 1s 9ms/step 157/157 ━━━━━━━━━━━━━━━━━━━━ 2s 9ms/step 157/157 ━━━━━━━━━━━━━━━━━━━━ 1s 9ms/step 157/157 ━━━━━━━━━━━━━━━━━━━━ 1s 9ms/step 157/157 ━━━━━━━━━━━━━━━━━━━━ 1s 9ms/step 157/157 ━━━━━━━━━━━━━━━━━━━━ 2s 10ms/step mse = 0.000388121648599426 standard deviation = 7.954220393637751e-06
Some predictions examples¶
def plot_n_predictions(n=4, batch_size=8):
generator = datagenerator(mnist_x_test,fashion_mnist_x_test, batch_size)
x, (y1, y2) = next(generator)
pred1, pred2 = model.predict(x)
n = min(n, batch_size)
fig, ax = plt.subplots(n, 3, figsize=(12, 4 * n))
for i in range(n):
input_image = x[i]
pred1_image = pred1[i]
pred2_image = pred2[i]
input_image = np.squeeze(input_image, axis=-1) if input_image.shape[-1] == 1 else input_image
pred1_image = np.squeeze(pred1_image, axis=-1) if pred1_image.shape[-1] == 1 else pred1_image
pred2_image = np.squeeze(pred2_image, axis=-1) if pred2_image.shape[-1] == 1 else pred2_image
# Plot Input Image
ax[i, 0].imshow(input_image, cmap="gray")
ax[i, 0].set_title("Input (MNIST + Fashion)")
ax[i, 0].axis("off")
# Plot MNIST Output
ax[i, 1].imshow(pred1_image, cmap="gray")
ax[i, 1].set_title("Predicted MNIST")
ax[i, 1].axis("off")
# Plot Fashion-MNIST Output
ax[i, 2].imshow(pred2_image, cmap="gray")
ax[i, 2].set_title("Predicted Fashion-MNIST")
ax[i, 2].axis("off")
plt.tight_layout()
plt.show()
plot_n_predictions(n=8)
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 33ms/step

Conclusion¶
The model proposed is inspired by the U-Net architecture with 3 blocks for encoder/decoder, skip connections and 3 convolutions per block. I decided to add batch normalization between each convolution step both in encoder and decoder stages. The number of starting filters is 64, they are doubled at each block during the encoder phase and they are halved during decoder phase. Skip connections ensure symmetrical block-wise feature sharing, resulting in pixel-perfect precision for both semantical (decoder) and positional (encoder) feature extraction.
Results¶
- The mean squared error (mse) against 50000 samples is 0.000388121648599426.
- Standard deviation of 7.954220393637751e-06 during tests.
Possible improvements¶
I would try to increase the starting amount of filters to 128 but this would certainly mean a parameters count explosion and increased training time. I'd also try to reduce the number of convolutions each block while keeping 128 as starting filters. This should balance training time, resulting in an even more precise network that isn't overly sophisticated. I believe there is no need for dropout because the model is not overfitting and apparently it can already generalize well. Data augmentation is also unnecessary due to the large volume of data.